1. 官方文档
API reference — pandas 2.2.2 documentation
2. 准备知识:Pandas 数据结构 Series & DataFrame
2.1 Series
2.1.1 创建 Series 类型数据
一个 Series 对象包含两部分:值序列、标识符序列。可通过 .values (返回 NumPy ndarry 类型数据) 和 .index (返回 Pandas Index 类型数据) 分别获取这两部分内容。
Pandas 中的 Index 对象是一个不可变的数组,用于标识 DataFrame 或 Series 中的行或列。Index 可以是整数、字符串或其他对象类型。
RangeIndex 是一种特殊类型的 Index,它是一个基于整数的 Index,用于表示连续的整数范围。 RangeIndex 是 Pandas 默认的Index类型,如果没有指定 Index 类型,则会自动使用RangeIndex。与普通的Index相比,RangeIndex 具有更高的性能,因为它不需要存储所有的值,而是只需要存储起始值、结束值和步长即可,此外,RangeIndex 还支持一些特殊的操作,如切片、重置索引等。
Series 可以有任意类型的显示索引 (可将其看作是行的标签 explicit index, label index) 。类似于 numpy.array,Series 也有隐式整数索引 (implicit index,位置索引 positional index),可指示元素在系列中的位置。如果创建 Series 时没有指定索引信息,显示索引采用隐式索引值。
类似于 dict,Series 也支持 .key() 和 in 关键字。
# s1 behaves like a Python dictionary because it features both a positional and a label index.
s1 = pd.Series([4200, 8000, 6500],index=["Amsterdam", "Toronto", "Tokyo"])
# s2 behaves like a Python list because it only has a positional index
s2 = pd.Series([5555, 7000, 1980])
# construct a Series with a label index from a Python dictionary
s3 = pd.Series({"Amsterdam": 5, "Tokyo": 8})
s1
s2
s3
# 返回结果:
# Amsterdam 4200
# Toronto 8000
# Tokyo 6500
# dtype: int64
# 0 5555
# 1 7000
# 2 1980
# dtype: int64
# Amsterdam 5
# Tokyo 8
# dtype: int64s1.values
# array([4200, 8000, 6500], dtype=int64)
s1.index
# Index(['Amsterdam', 'Toronto', 'Tokyo'], dtype='object')
type(s1.values)
# numpy.ndarray
type(s1.index)
# pandas.core.indexes.base.Index
type(s2.index)
# pandas.core.indexes.range.RangeIndex
s1.keys()
# Index(['Amsterdam', 'Toronto', 'Tokyo'], dtype='object')
s2.keys()
# RangeIndex(start=0, stop=3, step=1)
"Amsterdam" in s2
# False
"Amsterdam" in s3
# True2.1.2 获取 Series 中元素
way1: 索引操作符 (建议仅用于临时分析)
索引操作符方括号+索引 如:[label]
import pandas as pd
city_revenues = pd.Series({"Amsterdam": 4200, "Toronto": 8000, "Tokyo":6500})
city_revenues["Toronto"]
# 8000
city_revenues["Toronto":]
# Toronto 8000
# Tokyo 6500
# dtype: int64
# city_revenues[1] # 将弃用
# Series.__getitem__ treating keys as positions is deprecated. In a future version,
# integer keys will always be treated as labels (consistent with DataFrame behavior).
# To access a value by position, use `ser.iloc[pos]`
s1 = pd.Series([1, 4, 5, 8])
s1[3]
# 8
s1[2:4]
# 2 5
# 3 8
# dtype: int64way2: .loc[] & .iloc[] (推荐使用 pandas-specific access methods)
(1).loc[] 方法 (采用标签索引)
(2).iloc[] 方法 (采用位置索引)
.loc 和 .iloc 支持索引操作符的特性,如切片。不过,.loc 和 .iloc 有一个重要的区别:.iloc 不含最大值,但.loc 包含。
s1 = pd.Series({1: 'A', 2: 'B', 3:'C', 5:'D', 8:'E', 10:'F'})
# .loc[] 标签索引; .iloc[] 位置索引
s1.loc[1]
# 'A'
s1.iloc[1]
# 'B'
s1.loc[[1, 3, 5]]
# 1 A
# 3 C
# 5 D
# dtype: object
s1.iloc[[1, 3, 5]]
# 2 B
# 5 D
# 10 F
# dtype: object
# .iloc 不包括最大值,.loc 包含。
s1.loc[1:3]
# 1 A
# 2 B
# 3 C
# dtype: object
s1.iloc[1:3]
# 2 B
# 3 C
# dtype: object
s1.iloc[-1]
# 'F'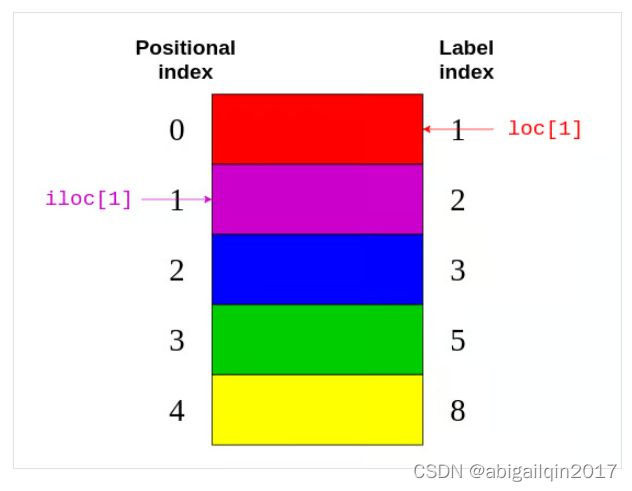
2.2 DataFrame
2.2.1 创建 DataFrame 类型数据
DataFrame 是一系列具有相同索引的 Series 对象。可通过在构造函数中传递字典 (字典键为列名,值为 Series 对象),将这些 Series 对象组合成一个DataFrame。
可以把 DataFrame 的两个维度称为坐标轴,.axes 返回轴信息,需要注意的是,0 对应行索引,1 对应列索引,了解这个术语很重要,因为很多 DataFrame 方法接受 axis 参数。
DataFrame 也是一种类似字典的数据结构,因此它也支持 .keys() 和 in 关键字。不过,对于一个DataFrame,这些与索引无关,而是与列名有关。
import math
import pandas as pd
import numpy as np
city_revenues = pd.Series({"Amsterdam": 4200, "Toronto": 8000, "Tokyo":6500})
city_employee_count = pd.Series({"Amsterdam": 5, "Tokyo": 8})
city_data = pd.DataFrame({
"revenue": city_revenues,
"employee_count": city_employee_count
})
city_data.index
# Index(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object')
city_data.values
# array([[4.2e+03, 5.0e+00],
# [6.5e+03, 8.0e+00],
# [8.0e+03, nan]])
city_data.axes
# [Index(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object'),
# Index(['revenue', 'employee_count'], dtype='object')]
type(city_data.index)
# pandas.core.indexes.base.Index
type(city_data.values)
# numpy.ndarray
type(city_data.axes)
# list
type(city_data.axes[0])
# pandas.core.indexes.base.Index注意 "Toronto" 缺少 employee_count 值,自动替换为 NaN。
math.isnan(city_data.iloc[2,1])
# True
np.isnan(city_data.iloc[2,1])
# True
pd.isna(city_data.iloc[2,1])
# True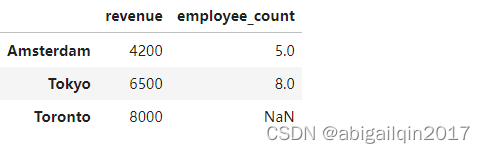
2.2.2 获取 DataFrame 中元素
way1: 索引操作符 (建议仅用于临时分析)
可使用索引运算符选择指定名称的列,如果列名是字符串,那么你也可以使用属性风格的点表示法访问 (当列名也是 DataFrame 属性或方法名时,不能采用点表示法)
import pandas as pd
city_revenues = pd.Series({"Amsterdam": 4200, "Toronto": 8000, "Tokyo":6500})
city_employee_count = pd.Series({"Amsterdam": 5, "Tokyo": 8})
city_data = pd.DataFrame({
"revenue": city_revenues,
"employee_count": city_employee_count
})
city_data['revenue']
# Amsterdam 4200
# Tokyo 6500
# Toronto 8000
# Name: revenue, dtype: int64
city_data.revenue
# Amsterdam 4200
# Tokyo 6500
# Toronto 8000
# Name: revenue, dtype: int64way2: .loc[] & .iloc[] (推荐)
1个参数 -- 行
city_data.loc['Tokyo']
# revenue 6500.0
# employee_count 8.0
# Name: Tokyo, dtype: float64
city_data.iloc[0]
# revenue 4200.0
# employee_count 5.0
# Name: Amsterdam, dtype: float64
city_data.loc['Tokyo':"Toronto"]
# revenue employee_count
# Tokyo 6500 8.0
# Toronto 8000 NaN2个参数 -- 行,列
city_data.loc[:, "revenue"]
# Amsterdam 4200
# Tokyo 6500
# Toronto 8000
# Name: revenue, dtype: int64
city_data.iloc[1:, :]
# revenue employee_count
# Tokyo 6500 8.0
# Toronto 8000 NaN当取单行或者单列时,需要注意返回值是 Series (int\str) 还是 DataFrame (list)。
city_data['revenue'] # Series
city_data[['revenue']] # DataFrame
city_data.iloc[1] # Series
city_data.iloc[[1]] # DataFrame
city_data.iloc[[]] # DataFrame3. 实践:数据的读取及初步查看
3.1 代码
import requests
import pandas as pd
import numpy as np
# 1.获取数据
download_url = "https://raw.githubusercontent.com/fivethirtyeight/data/master/nba-elo/nbaallelo.csv"
target_csv_path = "nba_all_elo.csv"
response = requests.get(download_url, verify=False)
response.raise_for_status() # Check that the request was successful
with open(target_csv_path, "wb") as f:
f.write(response.content)
print("Download ready.")
# 2. 读取数据
nba = pd.read_csv('nba_all_elo.csv')
# 3. 初步查看数据信息
len(nba)
nba.shape
pd.set_option("display.max.columns", None)
pd.set_option("display.precision", 2)
nba.head()
nba.info()
nba.dtypes
nba.describe()
nba.describe(include=object)
# 按条件筛选数据
current_decade = nba[nba["year_id"] > 2010]
current_decade.shape
# (12658, 23)
games_with_notes = nba[nba["notes"].notnull()]
games_with_notes.shape
# (5424, 23)
games_with_notes = nba[nba["notes"].notna()]
games_with_notes.shape
# (5424, 23)
ers = nba[nba["fran_id"].str.endswith("ers")]
ers.shape
# (27797, 23)
nba[(nba["_iscopy"] == 0) & (nba["pts"] > 100) & (nba["opp_pts"] > 100) & (nba["team_id"] == "BLB")]3.2 细节说明
3.2.1 获取数据:request 库
verify 参数
SSL证书:是数字证书的一种,类似于驾驶证、护照和营业执照的电子副本。因为配置在服务器上,也称为SSL服务器证书。SSL 证书就是遵守 SSL协议,由受信任的数字证书颁发机构CA(也可称为CA证书),在验证服务器身份后颁发,具有服务器身份验证和数据传输加密功能。
在使用 requests.get 时,如果请求的目标网站使用了自签名的SSL证书或者是无效的证书(SSLError异常),就需要设置 verify=False,这样可以忽略证书验证错误,使得请求可以正常发送。但是需要注意的是,这样做会存在一定的安全风险,因为无法保证请求的目标网站的身份和数据的安全性。因此,建议只在必要的情况下使用 verify=False。
verify参数适用场景
- https 类型网站,但是没有经过证书认证机构认证,考虑使用 verify 参数
- 程序中抛出 SSLError 异常,考虑使用 verify 参数

3.2.2 读入数据
read_csv 函数关键参数说明
- filepath_or_buffer:要读取的文件路径或者URL。
- sep:分隔符,默认为逗号。
- header:包含列名并标记数据开始(零索引)的行号。默认为 header=0,即第一行。header 可以是一个整数列表,用于指定 MultiIndex 的行位置,例如 [0,1,3]。未指定的中间行将被跳过。
- index_col:指定某一列作为行索引。
- usecols:指定要读取哪些列。
- dtype:指定应用于整个数据集或单个列的数据类型。例如,{'a': np。float64, 'b': np.int32, 'c': 'Int64'} 。
- skiprows:跳过前几行。
- nrows:读取的行数。
- na_values:指定哪些值为缺失值。
read_excel 函数关键参数说明
- io:要读取的Excel文件路径,可以是本地文件路径或URL。
- sheet_name:指定要读取的工作表名称或索引。
- header:指定哪一行作为列名,默认为0,即第一行。
- index_col:指定某一列作为行索引。
- usecols:指定要读取哪些列。
- dtype:指定列的数据类型。
- skiprows:跳过前几行。
- nrows:读取的行数。
- na_values:指定哪些值为缺失值。
3.2.3 初步查看数据信息
显示所有列
pd.set_option("display.max.columns", None)
pd.set_option("display.precision", 2)
nba.head()
所有列都能显示 (没有...)

查看每列的数据类型
.info()
.info() 除了可以各列的数据类型,还能显示数据缺失,以及内存占用情况。
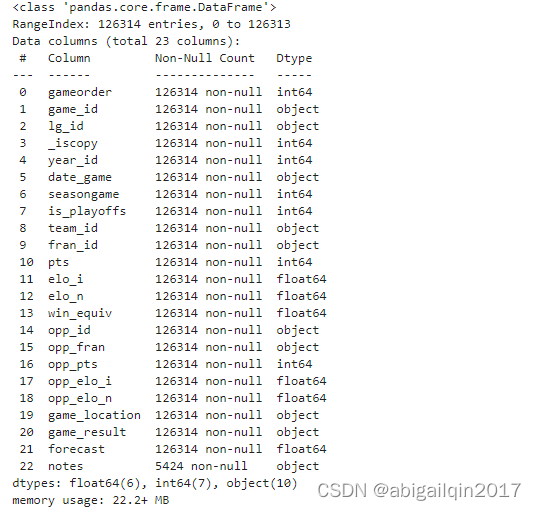
.dtypes
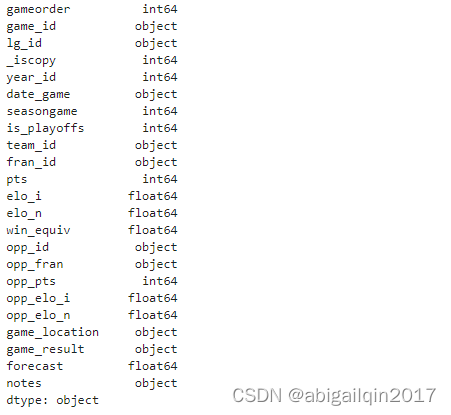
查看各列的描述性统计量
.describe()

.describe(include=object)

按条件查询数据
.notna() 和 .notnull() 方法在 pandas 中是等价的,它们都可以用于检查 DataFrame 或 Series 中的缺失值。这两种方法都返回一个布尔型的 DataFrame 或 Series,其中缺失值对应的位置为 False,非缺失值对应的位置为 True。
如需组合多个条件,将条件放在括号中,并使用操作符 | 和 & 来分隔。
- Python 的逻辑运算符有: and、not 和 or,优先级低于算术运算符,如<、<=、>、>=、!= 和 ==。
- pandas (以及NumPy) 不使用 and、or 或 not,而是使用 &、| 和 ~ (Python 内置位操作符,在pandas 和 NumPy 中,可以把 “按位” 想象成 “按元素”),它们的优先级高于 (而不是低于) 算术运算符,当在一个表达式中同时使用 & 运算符和算数运算符时,& 运算符会先被执行,如果想要改变运算顺序,需要使用圆括号来明确运算顺序。
4 < 3 and 5 > 4 # False 3 and 5 # 5 # 3 and 5 返回 5,是因为逻辑运算符 short-circuit evaluation,返回最后求值的实参 # 短路运算符(&&和||)在求值时,如果已经可以确定整个表达式的值,则不会继续求值剩余的部分,而是直接返回最后求值的实参的值。 # 具体来说,对于&&运算符,如果第一个实参为false,则整个表达式的值为false,不会继续求第二个实参; # 如果第一个实参为true,则整个表达式的值取决于第二个实参的值,会继续求值第二个实参并返回其值。 # 对于||运算符,如果第一个实参为true,则整个表达式的值为true,不会继续求值第二个实参; # 如果第一个实参为false,则整个表达式的值取决于第二个实参的值,会继续求值第二个实参并返回其值。 4 < (3 and 5) > 4 # Truepd.Series([True, True, False]) & pd.Series([True, False, False]) # 0 True # 1 False # 2 False # dtype: bool s = pd.Series(range(10)) # 带括号 -- 正确 (s % 2 == 0) & (s > 3) # 0 False # 1 False # 2 False # 3 False # 4 True # 5 False # 6 True # 7 False # 8 True # 9 False # dtype: bool # 不带括号 -- 报错 # s % 2 == 0 & s > 3 # 报错 # ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all(). # 等价于 (s % 2) == (0 & s) and ((0 & s) > 3) # 说明: Expansion the statement:x < y <= z is equivalent to x < y and y <= z. left = (s % 2) == (0 & s) # 0 True # 1 False # 2 True # 3 False # 4 True # 5 False # 6 True # 7 False # 8 True # 9 False # dtype: bool right = (0 & s) > 3 # 0 False # 1 False # 2 False # 3 False # 4 False # 5 False # 6 False # 7 False # 8 False # 9 False # dtype: bool # left and right # 报错 # The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all(). # The problem is that pandas developers intentionally don’t establish a truth-value (truthiness) for an entire Series. # Is a Series True or False? Who knows? The result is ambiguous. left & right # 0 False # 1 False # 2 False # 3 False # 4 False # 5 False # 6 False # 7 False # 8 False # 9 False # dtype: bool
4. DataFrame 常用操作
4.1 分组 Grouby & 聚合运算 agg
pandas 库提供了分组 Groupby 和聚合函数 agg 用以表达数据集的其他特征,例如分组统计元素的总和、平均值或平均值。
agg方法常与groupby一起使用,用于对分组后的数据进行聚合计算。agg 方法可以接受一个或多个聚合函数,将这些函数应用于每个分组,并返回一个DataFrame对象。
常用的聚合函数包括:
- sum():计算每个分组的总和。
- mean():计算每个分组的平均值。
- median():计算每个分组的中位数。
- min():计算每个分组的最小值。
- max():计算每个分组的最大值。
- count():计算每个分组的数量。
- std():计算每个分组的标准差。
- var():计算每个分组的方差。
示例1 下述代码用于描述:Golden State Warriors 队在2014-15赛季(year_id: 2015),在常规赛和季后赛中,胜负各有多少场。pandas 在调用 .groupby() 时会对组键进行排序。如果不需要排序,可以传递 sort=False,此参数可以提高性能。
nba[(nba["fran_id"] == "Warriors") & (nba["year_id"] == 2015)].groupby(["is_playoffs", "game_result"], sort=False)["game_id"].count()返回结果 (Series):
is_playoffs game_result
0 W 67
L 15
1 W 16
L 5
Name: game_id, dtype: int64
示例2 采用多个聚合函数时
nba_grp = nba.loc[(nba.loc[:,"year_id"] > 2013) & (nba.loc[:,"pts"] > 130)].groupby(['year_id',"team_id"])["pts"].agg(['count', 'mean'])
返回结果 (DataFrame 过长,此处仅展示部分内容):
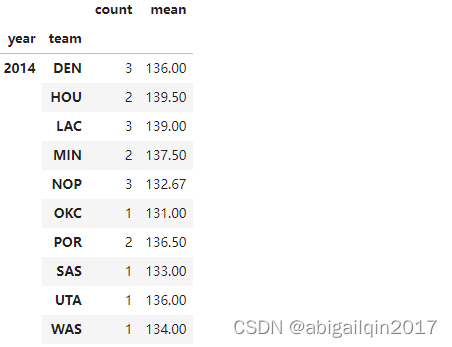
针对多重索引 DataFrame 的一些操作:
nba_grp.index.names = ['year', 'team'] # 修改多重索引名称
nba_grp.sort_index(level=0, axis=0) # 按行索引0 - year 排序
nba_grp.sort_index(level=1, axis=0) # 按行索引1 - team 排序
nba_grp.swaplevel(axis=0) # 交换多重索引级别
nba_grp.reset_index() # 展开为一维索引结果展示 (数据过长,此处仅展示部分内容):
| 原始表 | 改名+排序 (level0) | 排序 (level1) | 调换多重索引顺序 | 展平 | ||||||||||||||||
| count | mean | count | mean | count | mean | count | mean | year | team | count | mean | |||||||||
| year_id | team_id | year | team | year | team | team | year | 0 | 2014 | DEN | 3 | 136 | ||||||||
| 2014 | DEN | 3 | 136 | 2014 | DEN | 3 | 136 | 2015 | ATL | 1 | 131 | DEN | 2014 | 3 | 136 | 1 | 2014 | HOU | 2 | 139.5 |
| HOU | 2 | 139.5 | HOU | 2 | 139.5 | BOS | 1 | 132 | HOU | 2014 | 2 | 139.5 | 2 | 2014 | LAC | 3 | 139 | |||
| LAC | 3 | 139 | LAC | 3 | 139 | DAL | 5 | 136.4 | LAC | 2014 | 3 | 139 | 3 | 2014 | MIN | 2 | 137.5 | |||
| MIN | 2 | 137.5 | MIN | 2 | 137.5 | 2014 | DEN | 3 | 136 | MIN | 2014 | 2 | 137.5 | 4 | 2014 | NOP | 3 | 132.67 | ||
| NOP | 3 | 132.67 | NOP | 3 | 132.67 | 2015 | DEN | 1 | 143 | NOP | 2014 | 3 | 132.67 | 5 | 2014 | OKC | 1 | 131 | ||
| OKC | 1 | 131 | OKC | 1 | 131 | GSW | 3 | 133.33 | OKC | 2014 | 1 | 131 | 6 | 2014 | POR | 2 | 136.5 | |||
| POR | 2 | 136.5 | POR | 2 | 136.5 | 2014 | HOU | 2 | 139.5 | POR | 2014 | 2 | 136.5 | 7 | 2014 | SAS | 1 | 133 | ||
| SAS | 1 | 133 | SAS | 1 | 133 | LAC | 3 | 139 | SAS | 2014 | 1 | 133 | 8 | 2014 | UTA | 1 | 136 | |||
| UTA | 1 | 136 | UTA | 1 | 136 | MIN | 2 | 137.5 | UTA | 2014 | 1 | 136 | 9 | 2014 | WAS | 1 | 134 | |||
| WAS | 1 | 134 | WAS | 1 | 134 | NOP | 3 | 132.67 | WAS | 2014 | 1 | 134 | 10 | 2015 | ATL | 1 | 131 | |||
| 2015 | ATL | 1 | 131 | 2015 | ATL | 1 | 131 | 2015 | NOP | 1 | 139 | ATL | 2015 | 1 | 131 | 11 | 2015 | BOS | 1 | 132 |
4.2 增删行列、重命名等
下述代码包含修改列名、新增行\列、删除列\行、删除重复行\列、删除全为0的行\列、修改行名\列名。代码没有明确的实际含义,仅用于体现上述操作如何实现。
df = nba.iloc[:100, :].copy(deep=True)
# 新增行
## 增加一个重复行
df = pd.concat([df, df.iloc[[0]]], axis=0, ignore_index=True)
## 增加一个全为 NAN 的行
df_nan_row = pd.DataFrame([[np.nan] * df.shape[1]], columns=df.columns)
df = pd.concat([df, df_nan_row], axis=0, ignore_index=True)
# 新增列
df["difference"] = df.pts - df.opp_pts
## 新增一个新列 (原始数据中某列经过变换得到的)
df.insert(loc=1, column='year', value=df.loc[:, 'date_game'].apply(lambda v: v[-4:] if isinstance(v, str) and len(v) > 4 else v))
## 新增一个重复列,列名不重复,内容是重复的
df.insert(loc=2, column='game_id2', value=df.loc[:, 'game_id'])
## 新增一个重复列,列都是重复的
df.insert(loc=2, column='game_id', value=df.loc[:, 'game_id'], allow_duplicates=True)
# 删除某(几)行
df.drop(index=[1,2], inplace=True) # 当前索引序列为:0 3 4 5 ... (对应行的索引号将被删除)
df.iloc[:5, :5].head()
# gameorder year game_id game_id2 game_id
# 0 1.0 1946 194611010TRH 194611010TRH 194611010TRH
# 3 2.0 1946 194611020CHS 194611020CHS 194611020CHS
# 4 3.0 1946 194611020DTF 194611020DTF 194611020DTF
# 5 3.0 1946 194611020DTF 194611020DTF 194611020DTF
# 6 4.0 1946 194611020PRO 194611020PRO 194611020PRO
df.reset_index(drop=True, inplace=True) # 调整索引为顺序值:0 1 2 3 ...
df.iloc[:5, :5].head()
# gameorder year game_id game_id2 game_id
# 0 1.0 1946 194611010TRH 194611010TRH 194611010TRH
# 1 2.0 1946 194611020CHS 194611020CHS 194611020CHS
# 2 3.0 1946 194611020DTF 194611020DTF 194611020DTF
# 3 3.0 1946 194611020DTF 194611020DTF 194611020DTF
# 4 4.0 1946 194611020PRO 194611020PRO 194611020PRO
# 删除某(几)列
df.drop(columns=['lg_id'], inplace=True)
# 删除重复行
df.shape # (100, 26)
df.drop_duplicates(keep='last', inplace=True)
df.shape # (99, 26)
# 删除重复列
# df = df.T.drop_duplicates().T # 慎用
# 经过两次转置,原来列的数据类型可能会改变,但如果用drop会将同名的两个列都删掉
df = df.loc[:, ~df.T.duplicated(keep='first')]
df.shape # (99, 24)
# 删除全为0的行以及全为0的列 -- 当前数据没有全为0的行或列
df.drop(index=df.index[(df == 0).all(axis=1)], inplace=True)
df.drop(columns=df.columns[(df == 0).all(axis=0)], inplace=True)
df.shape # (99, 24)
# 去掉所有值都为 nan 的行
df.drop(index=df.index[df.loc[:, df.columns[df.dtypes != 'object']].map(lambda v: np.isnan(v)).all(axis=1)], inplace=True)
df.shape # (98, 24)
# 列重命名
df.rename(columns={"elo_i":"elo_n", "opp_elo_i":"opp_elo_n"}, inplace=True)
# 把某列设置为 index
df.insert(loc=0, column='id', value=range(1000, 1000+df.shape[0]))
df.set_index('id', inplace=True)
df.head()4.3. 设置数据类型
# 先整体看一下数据,判断字符串中第一位是月还是日
# 注意到有 10/31/1997,因此第一位是月
# nba['date_game'].value_counts()
nba.insert(loc=nba.columns.get_loc('date_game'),
column='date_game_dt',
value=pd.to_datetime(nba.loc[:,"date_game"], format='%m/%d/%Y'))
nba.head()
nba.drop(columns=['date_game'], inplace=True)
nba.head()
nba["game_location"] = pd.Categorical(nba.loc[:,"game_location"])
nba["game_result"] = pd.Categorical(nba.loc[:,"game_result"])
nba.dtypes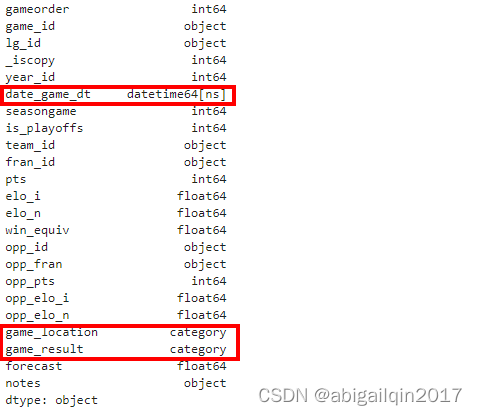
5. 实践:Cleaning Data 数据清洗
在数据分析过程中,初始拿到的数据通常从不同的源收集而来,可能存在错误、缺失值、重复值、异常值等问题,数据清洗是为了去除这些问题,使数据变得更加准确、可靠和有用。数据清洗的过程通常包括数据去重、数据填充、数据转换、数据规范化等步骤。通过数据清洗,可以提高数据的质量和可靠性,为后续的数据分析提供更好的基础。
5.1 缺失值
nba.shape
# way1:删除有缺失值的行或列
rows_without_missing_data = nba.dropna(axis=0)
rows_without_missing_data.shape
columns_without_missing_data = nba.dropna(axis=1)
columns_without_missing_data.shape
columns_without_missing_data.columns
# way2:填充
nba["notes"].fillna(value="no notes at all", inplace=True)5.2 异常值
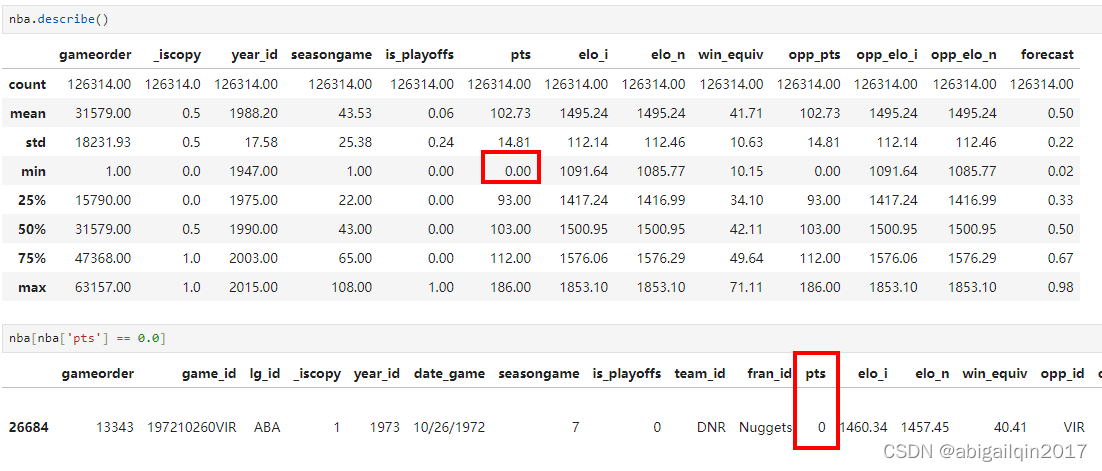
可以根据 describe() 结果,由数据范围初步判断是否有可能存在异常值。比如在当前的数据中,year_id 列中值的范围是:1947年~2015年,看起来很合理;但是 pts (投球得分) 列最小值是0,这显然不合理,进一步查询发现只有一行数据中,pts 为0,这场比赛可能被取消了,将这行数据从数据集中删去。
5.3 数据不一致
有时候,某个值真实存在没有缺失,但与其他列中的值不匹配,为此可以定义一些互斥的查询条件,验证是否有数据不一致的现象。
比如在当前数据集中,字段 pts、opp_pts 和 game_result 应保持一致 (结果为 “W” 时,pts 应大于 opp_pts;结果为 “L” 时,pts 应小于 opp_pts)。可以使用.empty属性来检查。
代码及结果如下,当前数据集不存在违反上述条件的条目。
nba[(nba["pts"] > nba["opp_pts"]) & (nba["game_result"] != 'W')].empty
# True
nba[(nba["pts"] < nba["opp_pts"]) & (nba["game_result"] != 'L')].empty
# True参考链接
【Python_requests学习笔记(四)】requests模块中verify参数用法_requests verify-CSDN博客
Using pandas and Python to Explore Your Dataset – Real Python